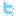




Исследования в маркетинге
Метод сегментации клиентских баз данных на основе жизненного цикла клиента
Источник: Электронный научный журнал «ИССЛЕДОВАНО В РОССИИ» 1875, http://zhurnal.ape.relarn.ru/articles/2006/200.pdf
Автор: Полежаев И.Е. ([email protected]), МИЭМ
Введение
Современный потребительский рынок характеризуется жесткой конкурентной борьбой за клиента. Информация о потребителе и история его покупок, собранная в клиентскую базу данных, дают огромное преимущество владельцу такой базы данных в конкурентной борьбе. Далее для словосочетания «база данных» мы будем использовать сокращение БД. Создание и управление клиентской БД, содержащей информацию о клиенте и историю взаимодействия с ним, для прямых предложений товаров и услуг компании называется директ-маркетингом. При этом компания–владелец БД ставит перед собой цель установить длительные взаимоотношения с клиентом и максимизировать прибыль, получаемую от клиента.
Сегодня практически каждая коммерческая организация ведет свою клиентскую БД. Это интернет магазины, сотовые операторы, директ-маркетинговые агентства, сети супермаркетов, сети ресторанов, аптечные сети, авиакомпании, туристические агентства и т.д. Современные технологии работы с клиентскими БД позволяют анализировать данные о клиентах и их потребительских предпочтениях и эффективно пользоваться полученной информацией, например:
- выполнять адресные рассылки с предложениями товаров или услуг по выбранной группе заинтересованных клиентов,
- отслеживать результаты маркетинговых акций: измерять процент отклика клиентов на предложения, а так же точно рассчитывать долю прибыли от рекламных инвестиций,
- оценивать качество групп клиентов, т.е. сегментировать клиентов на лояльных потребителей и не лояльных.
Самое важное преимущество директ маркетинга перед традиционными видами позиционирования товаров и услуг заключается в том, что этот инструмент предоставляет возможность целевого использования маркетинговых инвестиций с максимально возможной, точно рассчитанной отдачей. Это значит, что специфическая группа клиентов из БД получает предложение, которое интересно именно этой группе. Маркетинговые усилия фокусируются только на тех клиентах, которые с большой вероятностью откликнутся на коммерческое предложение, при этом меньше внимания уделяют тем клиентам, которые вероятно не отреагируют на данное предложение. В результате оптимизируется прибыльность от маркетинговых операций.
Например, магазин одежды собирается осуществить распродажу детской одежды. Вместо того чтобы отправить приглашения всем посетителям магазина, зарегистрированным в клиентской БД, почтовые открытки рассылаются только тем покупателям, которые ранее приобретали детские товары. Результатом такого целевого выбора является значительное сокращение затрат на рекламу распродажи и, соответственно, существенное увеличение доли рентабельности инвестиций (английский термин return on investment).
Другой пример. Производственное объединение выпускает новое моющее средство. Из всех клиентов базы данных формируются два списка адресов: (1) покупатели, заказывавшие бытовую химию ранее, и (2) клиенты, ранее не покупавшие бытовую химию. Создается специальное предложение, рекламирующее новое моющее средство и рассылается всей группе (1).
Создается специальное предложение «первая покупка моющего средства» и рассылается только по части группы (2), т.е. проводится тест на репрезентативной выборке из (2) группы. В случае успеха теста, предложение рассылается оставшимся клиентам из (2) группы. В случае неуспеха, средства либо экономятся, либо разрабатывается другое, более привлекательное предложение.
Таким образом, директ маркетинг позволяет принимать более корректные маркетинговые решения, которые основываются на реальных фактах — знаниях, которые несет информация, содержащаяся в клиентской БД. В результате увеличивается как объем продаж, так и рентабельность инвестиций. При этом клиенты директ маркетинговой компании, в случае правильно организованных целевых акций избавлены от нежелательных писем (spam, junk mail).
Однако, несмотря на бесспорные преимущества, прямой маркетинг характеризуется большими рисками. Одна неправильно спланированная акция может сильно ухудшить позицию фирмы на рынке вплоть до ее разорения: например, почтовая рассылка с миллионным бюджетом может быть направлена нецелевому сегменту. Чтобы оградить себя от рисков, спрогнозировать будущее развитие, сформулировать долгосрочную стратегию, компании инвестируют большие средства в аналитическую работу с клиентскими БД. Грамотная сегментация клиентской БД, анализ и тестирование информации, содержащейся в БД, прогнозирование состояния клиентской БД позволяют компаниям избежать рисков и выжить в конкурентной борьбе.
Настоящая работа посвящена созданию усовершенствованного метода сегментации клиентских БД. Новый метод базируется на анализе жизненного цикла клиента и снимает ряд существенных ограничений известных ныне методов сегментации. Ограничения касаются корректности оценивания статистической информации по результатам маркетинговых тестов в рамках клиентских сегментов и возможности прогнозирования состояния клиентской БД в будущем.
Статья организована следующим образом. В разделе «Постановка задачи» приводится вербальная и математическая постановка задачи и объясняется прикладной смысл такой постановки задачи. В разделе «Обзор существующих методов» приводится анализ существующих методов сегментации клиентской БД, описание типовых моделей клиентского поведения и формулируются основные ограничения существующих ныне методов. В разделе «Новый метод сегментации» приводится новый метод сегментации, разработанный автором. Новый метод основывается на анализе поведения клиентов на различных этапах жизненного цикла. Сегментация является средством анализа базы данных, поэтому в разделе «Анализ состояния клиентской БД» приводится ряд методик, позволяющих анализировать состояние клиентской БД в рамках построенной сегментации. В разделе «Апробация метода» приводится пример применения разработанного метода для анализа БД держателей дисконтных карт одной из московских сетей. В разделе «Выводы» кратко формулируются итоги исследования. В разделе «Список литературы» приводятся ссылки на использованные источники.
Постановка задачи
Перейдем к постановке задачи сегментации клиентской БД. Вербально постановка задачи звучит так. В любой момент времени на основе предыдущей клиентской истории необходимо ответить на вопрос: заслуживает ли клиент «А» разрабатываемого маркетингового предложения. Эту задачу еще называют задачей целевого выбора.
Формальная постановка задачи. Набор данных в рассматриваемой задаче D представляет собой таблицу из N элементов (записей), описываемых l отдельными атрибутами h1, h2, …, hl. Атрибут может быть как числовой, так и категориальной переменной. Запись (строка) Xi = (h1i, h2i, …,hli) представляет собой поведенческую историю клиента Xi на момент расчета таблицы D. Все N наблюдений заранее отнесены к одному из двух классов С1 и С2. В практических приложениях только один из этих двух классов является целевым классом и, как правило, является миноритарным, т.е. класс покупателей в директ маркетинге. Этот класс еще называют позитивным классом, а наблюдения из рассматриваемого класса позитивными наблюдениями. Второй класс называют негативным классом. На практике позитивный класс кодируют 1, а негативный класс — 0. Соответствующий столбец в наборе данных D представляет собой переменную — учитель class.
Задача сегментации состоит в построении классификатора, позволяющего:
- Присвоить вероятность принадлежности наблюдения позитивному классу Pi = F (h1i, h2i, …, hli). Эту вероятность еще называют скором (от английского score – баллы, очки), а модель классификатора, соответственно скоринговой моделью, или просто скорингом.
- Объединить близкие по вероятности отклика наблюдения в k>2 сегментов.
В большинстве работ, посвященных задаче целевого выбора, авторы ограничиваются первым пунктом приведенной постановки задачи. Но целью нашего исследования является создание нового метода сегментации, а не решение задачи скоринга. Поэтому, с целью преемственности предыдущих результатов и полноты исследования, мы оставляем привычную постановку задачи и усиливаем ее пунктом 2.
Возникает разумный вопрос: почему именно сегментация а не скоринг? Ведь из постановки задачи, очевидно, что построение сегментации дает более грубый результат, нежели скоринг: в случае скоринга мы имеем дело с персональными оценками вероятности отклика, а в случае сегментации будем обладать лишь групповой оценкой. Сделаем необходимые пояснения. Пункт 2 в постановке задачи имеет важный прикладной смысл и представляет собой отдельную задачу классификации наблюдений по вероятности отклика на большее количество мелких сегментов, нежели только позитивный и негативный классы. Работа с более мелкими классами, дает возможность планирования и анализа выборочных маркетинговых экспериментов на уровне сегментов, построения статистических оценок прибыльности акций и принятия решения о дальнейшей экстраполяции маркетинговой концепции на всю клиентскую базу данных D или ее часть. Кроме того, дробление на сегменты позволяет применять к полученным сегментам диверсифицированный подход (по силе маркетингового предложения, размеру скидки, типу подарков и т.д.). Таким образом, тестирование, статистический анализ и экстраполяция результатов маркетинговых экспериментов в рамках сегментов дает возможность управлять состоянием клиентской БД. Под состоянием клиентской БД в момент времени t будем понимать распределение наблюдений по сегментам в рамках разработанной сегментации.
Обзор существующих методов
Различные исследования в области директ — маркетинга приходят к единому выводу: наиболее сильное влияние на принадлежность наблюдений позитивному классу оказывают переменные поведенческой истории клиента, нежели результаты анкетирования клиента см. [12]. Поэтому, в большинстве своем все модели сегментации ограничиваются универсальной тройкой переменных, известных как RFM по первым буквам названий переменных см. [13]. Итак, в нашем случае h1 = R, h2 = F, h3 = M.
- Recency (R) — давность последнего заказа. Рассчитывается как разность, выраженная в днях, между текущей датой и датой последнего заказа.
- Frequency (F) — общее количество заказов, сделанных клиентом за всю историю наблюдения за клиентом.
- Monetary (M) — общее количество денег, потраченных клиентом за всю историю.
Предикторы RFM используются для прогнозирования принадлежности позитивному классу ввиду того, что историческое покупательское поведение зачастую является надежным ориентиром, говорящим о будущем покупательском поведении см. [15,18]. Более того, поведение клиентов во всех видах директ–маркетинга следует по одинаковым RFM законам. Например, вероятность повторной покупки по почтовому каталогу и вероятность повторного посещения сети ресторанов имеет одинаковую форму зависимости от RFM переменных. Меняются лишь значения коэффициентов в формулах зависимостей, знаки же коэффициентов, а соответственно и виды кривых зависимостей остаются. Таким образом, можно говорить о RFM постулатах клиентского поведения.
Ниже описываются типовые зависимости вероятности повторного заказа (принадлежности позитивному классу) от RFM переменных, подтверждаемые большим количеством экспериментальных данных.
R-постулат. Вероятность принадлежности позитивному классу отрицательно зависит от recency: чем больше времени прошло с момента последнего заказа, тем меньше вероятность будущего заказа. Типичный вид кривой recency см. на рисунке ниже.
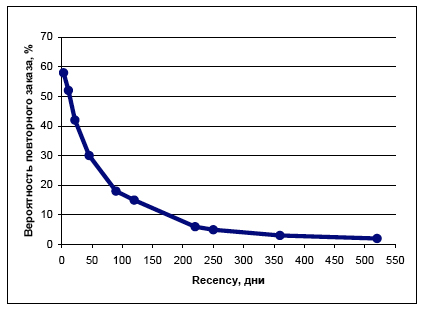
Рисунок 1. Зависимость вероятности повторного заказа от давности последнего заказа резко убывающая
Повторный заказ подразумевает некоторую системность в поведении клиента, иначе говоря, привычку, или приобретение таковой. Клиенту свойственно делать заказ повторно через не очень большой промежуток времени, т.е. пока покупатель еще не забыл о существовании фирмы, с которой взаимодействует. Более того, приобретая привычку, покупатель ощущает необходимость делать привычной действие все чаще. Соответственно, частота при наступлении привычки и все уменьшающийся промежуток времени между повторными, привычными действиями объясняет эмпирический постулат recency. Когда же покупатель теряет привычку, интервал между последним его заказом и будущим, которого, скорее всего, не будет уже никогда, вырастает до бесконечности. Эффект частоты и промежутка времени между последующими действиями открывает еще один постулат, который объясняется ниже.
F-постулат. Вероятность принадлежности позитивному классу положительно зависит от frequency: чем больше заказов сделал клиент, тем больше вероятность, что он сделает еще один заказ. Этот постулат очевиден и не требует особых пояснений. Типичный вид кривой frequency см. на рисунке ниже.
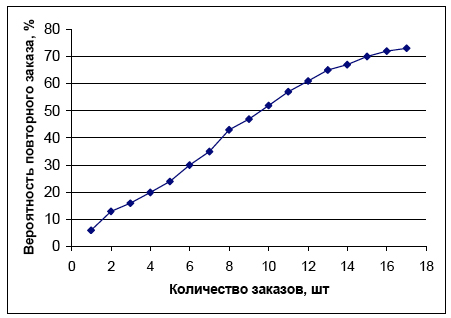
Рисунок 2. Зависимость вероятности повторного заказа от количества сделанных заказов почти линейная с насыщением в области больших значений
M-постулат. Вероятность принадлежности позитивному классу положительно зависит от monetary: чем больше потрачено денег, тем больше вероятность будущего заказа. Этот постулат так же очевиден и не требует особых пояснений. Типичный вид кривой показан на рисунке ниже.
Предсказательная мощность перечисленной тройки переменных ранжируется аналогично последовательности букв в названии RFM: recency является наилучшим предиктором, вторым идет frequency и последним по силе является monetary см. [11].
Следует отметить что, переменные RFM коррелируют между собой. Как уже упоминалось выше, частота при наступлении привычки и все уменьшающийся промежуток времени между повторными, привычными действиями объясняет эмпирический постулат recency. Соответственно, чем меньше recency, тем больше frequency, т.е. R и F коррелируют между собой отрицательно. Так же очевидно, что M и F прямо пропорциональны: чем больше заказов делает клиент, тем больше средств он тратит на эти заказы. Соответственно M и F коррелируют положительно. Аналогично паре F и R, корреляция между F и M отрицательна.
Построение моделей. Сравнение эффективности методов.
В большинстве приложений, на выходе построенной модели получается число p, принимающее значение в интервале от 0 до 1, которое трактуется как вероятность принадлежности записи Xi = (h1i, h2i, …, hli) позитивному классу. Для решения задачи скоринга применяются следующие методы прикладной статистики: линейная и нелинейная регрессия (см. описание методов и их применение [1,2,4,5, 19, 20]), нейронные сети [7,8,12,19], деревья решений [5,6,19], дискриминантный анализ [3,5,6], ассоциативные правила [10,16,17,19, 20] и др.
Сравнение различных классических подходов методом кросс — проверки см. [19] и методом построения карт выигрышей см. [20] на идентичном наборе данных с RFM предикторами показывает приблизительно одинаковое качество построенных классификаторов. Перечисленные методы дают достаточную эффективность и применяются в различных директ-маркетинговых компаниях при решении задачи целевого выбора.
Кроме инструментов прикладной статистики для задачи сегментации применяются другие методы, также базирующиеся на RFM переменных. Самым простым и наиболее широко применяемым на сегодняшний день методом сегментации клиентских баз данных является метод RFM кодирования, или просто RFM сегментация [14,11]. Суть его состоит в следующем: значения каждой переменной (R, F и M) разбиваются на 5 интервалов по квинтилям распределения клиентов, либо по квинтилям распределения значений переменной. Каждая полученная группа кодируется значениями от 1 до 5 в соответствии с постулатами клиентского поведения: 1 присваивается наименее вероятной группе, 5 наиболее вероятной.
Ниже приводится алгоритм простейшего RFM кодирования.
1. Все наблюдения файла данных D сортируются по возрастанию значения recency (R). После сортировки файл данных делится на 5 равных частей: в первый квинтиль попадают наиболее «свежие» клиенты, во второй — вторые по давности последнего заказа и т.д. Каждый квинтиль кодируется. Код 5 присваивают самому «свежему» квинтилю, код 4 — второй по давности последнего заказа группе и т.д. (см. таблицу ниже).
| Qty | R |
| N/5 | 5 |
| N/5 | 4 |
| N/5 | 3 |
| N/5 | 2 |
| N/5 | 1 |
| Qty | F |
| N/5 | 1 |
| N/5 | 2 |
| N/5 | 3 |
| N/5 | 4 |
| N/5 | 5 |
Таблица 2. После сортировки файла D по возрастанию frequency (F) проводится группировка на 5 одинковых по объему (N/5) групп клиентов и кодирование сегментов от 1 до 5. Значение 1 получают самые «слабые», т.е. худшие с точки зрения F клиенты, значение 5 получают лучшие с точки зрения F клиенты.
3. Все наблюдения файла данных D сортируются по возрастанию значения monetary (M). После сортировки файл данных делится на 5 равных частей: в первый квинтиль попадают клиенты, потратившие наименьшее количество средств, во второй — вторые по количеству истраченных денег и т.д. Каждый квинтиль кодируется. Код 1 присваивают самому «слабому» с точки зрения потраченных денег квинтилю, код 2 — второй по количеству денег группе и т.д. (см. таблицу ниже).
| Qty | M |
| N/5 | 1 |
| N/5 | 2 |
| N/5 | 3 |
| N/5 | 4 |
| N/5 | 5 |
Таблица 3. После сортировки файла D по возрастанию monetary (M) проводится группировка на 5 одинковых по объему (N/5) групп клиентов и кодирование сегментов от 1 до 5. Значение 1 получают самые «слабые», т.е. худшие с точки зрения M клиенты, значение 5 получают лучшие с точки зрения M клиенты.
Всевозможные комбинации кодов RFM дают 125 (= 53) сегментов. Таким образом, 555 заранее является наилучшим сегментом, 111 — наихудшим. Вероятности отклика внутри сегментов находятся экспериментально. По случайной выборке из каждого из 125 сегментов проводится рассылка, затем фиксируется процент отклика в каждом сегменте, который представляет собой оценку вероятности отклика. Таким образом, RFM сегментация представляется собой неявную функцию, ставящую в соответствие каждому из 125 сегментов вероятность отклика.
Итоги обзора существующих методов сегментации БД
Анализ существующих методов показывает, что, хотя все применяемые методы и решают задачу сегментации клиентской БД, они обладают одним общим недостатком: нефиксированные границы отсечения по вероятности отклика.
Действительно, если при пересчете сегментации распределения клиентов по RFM переменным изменится, соответственно границы отсечения сегментов изменятся. Например, при пересчете сегментации может оказаться, что сегмент 5 по R образуют клиенты с R<2 месяца, а при пересчете в следующий период наблюдения окажется, что сегмент 5 по R образуют клиенты с R < 2.5 месяца.
В виду того, что границы не фиксированы, методы сегментации, вообще говоря, не позволяют:
- проводить выборочные тесты новых маркетинговых концепций в рамках сегментов и получать статистические оценки вероятности отклика на них с целью дельнейшей экстраполяции результатов на весь сегмент, т.к. в виду изменения границ сегментов, статистические оценки тестов являются ненадежными [20],
- отслеживать динамику развития БД. Один класс не является этим же классом в следующий момент времени.
Разработанный метод позволяет устранить ограничения существующих подходов.
Новый метод сегментации
Разработанный метод сегментации базируется на RFM переменных, приведенных постулатах клиентского поведения и выводах о прогнозной силе RFM переменных. Предлагаемый метод отличается от существующих методов тем, что он основывается на предварительном анализе цикличности заказов клиента и имеет фиксированные границы отсечения по всем участвующим переменным. Ввиду универсальности RFM законов и универсальности выводов о цикличности клиентского поведения предлагаемый метод может применяться во всех видах дистанционного маркетинга.
Как было сказано выше, R является наиболее сильным предиктором, F является вторым по силе, M — третьим. В разработанном методе предлагается проводить сегментацию в соответствии с прогнозной силой переменных. Сегментация проводится в три этапа.
- Проводится сегментация по R на 3 сегмента: сегмент активных клиентов, сегмент спящих клиентов и переходный сегмент. Сегментация проводится на основе анализа цикличности заказов клиента и анализа профиля кривой R, которая сама по себе характеризует основные этапы жизненного цикла клиента.
- Ввиду того, что F вторая по прогнозной силе переменная, проводится уточнение сегментации по F. Детализация по F затрагивает спящий и переходный сегменты и не применяется к сегменту активных клиентов, т.к. такая необходимость отсутствует. На этом этапе применяются разработанные в настоящей работе метод отсечения одного заказа и метод группировки по процентилям.
- Последний этап является факультативным. В случае необходимости по спящим клиентам с F=1 проводится сегментация по M методом квинтилей.
Сегментация по предиктору давность R
Зависимость вероятности повторного заказа от recency резко экспоненциальная, отрицательная. Причем, в то время как переменные F и M обладают кумулятивной природой, то значение R обнуляется при каждом очередном заказе клиента. В основе переменной R лежит простая идея: все клиенты делятся на 2 группы — активные клиент и неактивные клиенты, или их еще называют спящими клиентами. А значение, которое принимает переменная R, говорит о том, какой из двух перечисленных групп принадлежит клиент. Делая заказ, клиент автоматически переходит в группу активных клиентов, в противном случае, через некоторое время клиент считается спящим. Таким образом, переменная R сама по себе является самодостаточным фактором сегментации [14] и описывает основные этапы жизненного цикла клиента. Фактически, профиль кривой R представляет собой графическое представление жизненного цикла клиента (см. Рисунок 4).
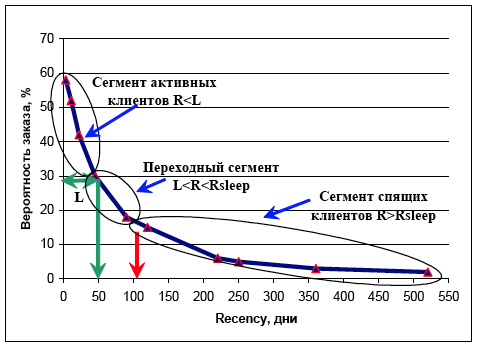
Рисунок 4. Форма кривой давности последнего заказа R описывает основные этапы жизненного цикла клиента. На основании этого факта, проводится первый этап сегментации на 3 сегмента «Активные клиенты», «Спящие клиенты» и «Переходный сегмент»
Зона больших значений вероятности отклика при малых значениях R — это зона активных клиентов. Находясь в этой зоне, клиент «переживает» пик своей активности и приносит максимальную прибыль. Зона малых значений вероятности отклика и больших значений R — это зона спящих клиентов. Находясь в этой зоне, клиент «доживает» свою историю взаимодействия с компанией. Такие клиенты не приносят прибыли и очень рискованны для постоянного использования.
В разработанном методе сегментации переменная R несет первообразующую роль. Ключевая идея метода сегментации по R заключается в том, чтобы, проанализировав цикличность в поведении клиента, разбить область возможных значений recency (0, +∞) на 3 интервала, определяющих сегмент активных клиентов, сегмент спящих клиентов и переходный сегмент.
Сегмент активных клиентов.
Введем показатель Latency (L) равный усредненному по всем клиентам среднему интервалу между последующими заказами. По определению значение L характеризует частоту заказов усредненного клиента и несет информацию о поведенческом цикле этого клиента. Таким образом, усредненный клиент заказывает каждые L дней.
Очевидно, что если для конкретного клиента X давность последнего заказа превышает средний интервал между заказами RX>L, то можно предположить, что клиент «затягивает» с принятием решения о последующем заказе и, возможно, больше заказывать не собирается. В этом случае можно говорить о том, что клиент меняет поведение, и уже вошел в зону риска прекращения взаимодействия с компанией, или переходную зону. Значит, проводя отсечение значения переменной давности последнего заказа как R = R(0, L), определяется сегмент активных клиентов.
Показатель L так же дает ответ о частоте пересчета (обновления) сегментации. Так как усредненный клиент в течение периода L сохраняет свое поведение, то нет смысла проверять его принадлежность тому или иному сегменту чаще, чем каждые L месяцев. Поэтому в пассивном режиме стоит пересчитывать сегментацию каждые L месяцев. Так же рекомендуется обновлять сегментацию перед подготовкой клиентских адресов для маркетинговой акции.
Сегмент спящих клиентов.
Для выявления сегмента спящих клиентов предлагается применять метод каменистой осыпи. По исторической рассылке строится график зависимости процента отклика от R. На полученном графике выявляется область значений R = R(Lsleep,+∞), на которой значения процента отклика перестают существенно меняться и представляют собой шум в районе нулевых значений процента отклика.
Переходный сегмент.
Переходный сегмент однозначно определяется сегментом активных клиентов и сегментом спящих клиентов по отсечению давности последнего заказа R=R(L, Lsleep). Переходный сегмент образует так называемую «серую зону», зону неопределенности «активен ли клиент, или уже нет?». Действительно, показатель L является усредненной оценкой частоты заказов по всем клиентам. Очевидно, что оценка LX для каждого клиента X своя, в общем, отличная от L. То есть каждый клиент обладает своим персональным циклом, и появление зоны неопределенности является своеобразной платой за усреднение частоты заказов по всем клиентам. Полностью избавиться от зоны неопределенности невозможно, можно лишь ее сократить. Этап сегментации по F, рассматриваемый в следующем разделе, во многом решает эту задачу.
Проверка разбиения на статистическую значимость.
Получив 3 сегмента: активных клиентов, спящих клиентов и переходный сегмент необходимо проверить разбиение на статистическую значимость. Для этого предлагается применять биномиальный критерий. Достаточно проверить статистически значимые различия в наблюдаемых вероятностях отклика для двух пар сегментов:
- Активные клиенты и переходный сегмент, p-уровень <0.05
- Спящие клиенты и переходный сегмент, p-уровень <0.05
При выполнении перечисленных условий статистически значимое различие между сегментом активных клиентов и сегментом спящих клиентов следует автоматически. Сегментация по R закончена.
Сегментация по предиктору частота F
При сегментации по F основное внимание уделяется двум последним сегментам, т.к. сегмент активных клиентов по построению не требует дополнительной группировки. Этап сегментации по F преследует 2 цели:
- сокращение зоны неопределенности переходного сегмента и
- выявление группы спящих клиентов, наиболее предрасположенных для получения предложений.
Для F сегментации по переходному и спящему сегментам предлагается применять 2 разработанных правила: отсечения одного заказа и группировки по процентилям.
Правило отсечения одного заказа.
Во многих клиентских БД наблюдается очень большой процент клиентов, которые сделали только один заказ и стали спящими. Этот процент зачастую составляет 30%-60% [14]. Стоит также заметить, что дальнейшее поведение клиента, сделавшего один заказ, значительно отличается от поведения клиента, который заказал 2 и более раз (см. Рисунок 2 в области 1, 2 заказов виден существенный перепад вероятности отклика). Маркетологи объясняют это явление тем, что клиент, сделав один заказ, всего лишь пробует предлагаемый способ дистанционного взаимодействия, а, сделав второй, действительно становится клиентом. Соответственно, 30%-60% клиентов сделали пробный заказ и более не приемлют взаимодействия с компанией. Очевидно, что такая многочисленная группа клиентов, обладающих схожей историей поведения, а, следовательно, предполагающая похожее поведение в будущем должна рассматриваться отдельно. Чтобы учесть отмеченный немаловажный факт, разработано правило отсечения одного заказа на этапе F сегментации.
Правило отсечения одного заказа по F определяет разбиение спящего и переходного сегментов на 2 группы:
- клиенты, сделавшие только 1 заказ и
- клиенты, сделавшие 2 и более заказов (обозначается 2+).
Эффективность разбиения проверяется биномиальным критериев аналогично правилу, описанному в предыдущем разделе.
Правило отсечения границ по процентилям.
После применения правила отсечения одного заказа, вычисляется доля клиентов в сегменте 2+. Если сегмент 2+ оказывается многочисленным (перенаселенным), то его следует разделить. Действительно, пользуясь F-постулатом клиентского поведения можно утверждать, что дополнительное дробление по F позволит выделить наиболее перспективный сегмент в рамках переходного сегмента, что фактически позволит сократить сам переходный сегмент. Если же речь идет о сегменте спящих клиентов, то такая дополнительная группировка по F выделит наиболее перспективную группу клиентов для реанимации.
Введем критерий перенаселенности сегмента 2+. Сегмент 2+ считается перенаселенным, если он содержит более 25% клиентов всей БД и более 50% всех клиентов переходного или спящего сегментов. Итак, если выполняется критерий перенаселенности сегмента 2+, то к нему применяется правило отсечения границ по процентилям.
Алгоритм правила отсечения границ по процентилям следующий.
- Все клиенты сегмента 2+ делятся на процентили по значениям F. Значение требуемого процентиля очевидным образом следует из объема рассматриваемого сегмента. Как правило, достаточно ограничиться квинтилями.
- Затем графически определяются зоны отсечения по F, характеризующие существенные различия в вероятности отклика так, чтобы результирующие сегменты после группировки содержали достаточное количество клиентов, скажем, не менее 5% всех клиентов БД.
Минимальная доля клиентов в результирующем сегменте определяется соображениями здравого смысла и преследуемыми целями. С одной стороны, клиентов не должно быть очень мало, т.к. наличие сегмента подразумевает разработку отдельной стратегии, применяемой к полученному сегменту на постоянной основе. Еще один аргумент в пользу укрупнения — это возможность тестирования сегмента и получения значимых статистических оценок вероятности отклика. С другой стороны, клиенты, принадлежащие сегменту, должны обладать максимально схожими характеристиками, поэтому клиентов, обладающих явно различным поведением, стоит разделять.
Проверка F разбиения на статистическую значимость.
После применения правила отсечения одного заказа и правила группировки по процентилям проводится проверка на значимость разбиения. Значимость разделения вероятностей отклика по k полученным сегментам последовательно проверяется биномиальным критерием. Сегменты, не выявляющие статистически значимые различия в клиентском поведении, обратно объединяются в один сегмент. После вынужденного объединения сегментов, проводится повторная последовательная проверка разбиения биномиальным критерием.
Алгоритм можно представить так:
- Пока для всех i от 1 до k-1 не выполнится pBi(Si,Si+1)<0,05
выполнять:
- Если pBi(Si,Si+1)≥0.05, то Si=Si U Si+1 где pBi(Si,Si+1) — p-уровень значимости биномиального критерия, применяемого к двум последовательным сегментам Si,Si+1.
Таким образом, сохраняя численную представимость сегментов с одной стороны, статистическую контрастность разбиения с другой, осуществляется сегментация по F. Важно отметить, что после определения границ отсечения, значения этих границ фиксируются, т.е. при обновлении сегментации в следующий период времени пересчет по процентилям не производится.
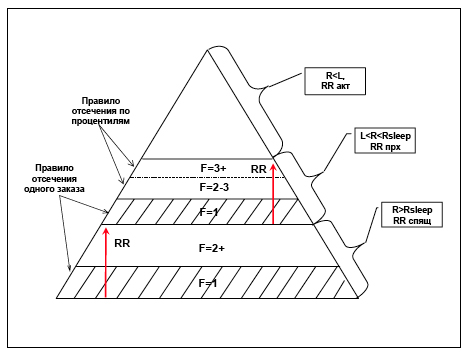
Рисунок 5. Иллюстрация сегментации по F. Сначала применяется правило отсечения одного заказа, затем для сегментов 2+ применяется правило отсечения по процентилям. В настоящем примере правило группировки по процентилям затронула только переходный сегмент в области перехода заначений F: 2->3. Для сегмента спящих клиентов результаты группировки по процентилям оказались статистически незначимыми. Стрелками внутри сегментов показаны «направления» увеличения вероятности отклика в соответствии с F постулатом. Сегментация по F завершена.
Сегментация по предиктору прибыль M
Выше уже упоминалось, что в большинстве приложений переменные F и M имеют сильную взаимную корреляцию (~0.9). Очевидно, что чем больше заказов делает клиент, тем больше денег он тратит. Безусловно, переменная M объясняет некоторую дополнительную долю дисперсии в дополнении к F, но этим незначительным фактом можно пренебречь, особенно при построении сегментации для разработки маркетинговой стратегии. В случае необходимости, пользуясь M-постулатом клиентского поведения, для спящего или переходного сегментов с F=1 можно применить метод отсечения по процентилям. Итоговую сегментацию необходимо проверить на значимость биномиальным критерием и объединить сегменты, в которых различия в вероятности отклика оказываются незначимыми. Сегментация построена.
Анализ состояния клиентской БД
Сегментация клиентской БД сама по себе является средством анализа состояния клиентской БД. Основное достоинство нового метода сегментации — это фиксированные границы отсечения значений переменных, что позволяет сравнивать состояние базы данных в базисе такой сегментации в разные моменты времени. Будем говорить, что после построения сегментации S с фиксированными границами задан аналитический базис S.
Введем необходимые термины и обозначения. Предположим, что сегментация S построена. В момент времени t клиенты БД по установленным правилам разделяются на сегменты S = {A0, A1…, Ak}. Границы отсечения сегментов Ai фиксированы по значениям переменных, которые определены жизненным циклом клиента и другими разработанными правилами. Каждый сегмент Ai в момент времени t содержит Ni(t) клиентов. Набор DN(t) = {N0(t), N1(t), …, Nk(t)} назовем состоянием клиентской БД в момент времени t в базисе сегментации S.
За один период времени L клиентская БД переходит из состояния S(t) в состояние S(t+1). При этом состояние БД в базисе сегментации S может либо улучшиться, либо ухудшиться, или остаться таким же.
Будем считать, что состояние БД ухудшилось за один период времени L, если доля активных клиентов (R
Динамическое сравнение сегментов по объему
Самой простой, очевидной и наглядной методикой выявления и предотвращения негативных тенденций в эволюции клиентской БД является метод динамического сравнения сегментов клиентской БД по объему. По построению сегмента Ai в базисе сегментации S можно однозначно сказать, каких клиентов содержит сегмент: активных, спящих, или клиентов переходного состояния.
Рассмотрим сегмент Ai в базисе сегментации S в два последовательных интервала времени S(t) и S(t+1). Обозначим долю клиентов, которая приходится на сегмент Ai в момент времени t как:
% Ni(t) = Ni(t) / N(t)
На основании динамики доли объема сегмента Ai: %Ni(t)→%Ni(t+1) и априорной информации о качестве сегмента принимается решение является ли динамика сегмента положительной или отрицательной.
- Очевидно, что для активной зоны динамика должна быть неотрицательной: %Ni(t+1) ≥ %Ni(t), где Ai:R
- Желательно, чтобы для сегмента спящих клиентов и переходного сегмента динамика была отрицательной: %Ni(t+1) ≤ %Ni(t), где Ai:R>L.
В случае выявления негативных тенденций выявляются их причины, и разрабатывается комплекс мер для их устранения.
Финансовый анализ клиентской БД
Факт заказа (его давность R), как обсуждалось ранее, является первичной характеристикой, определяющей будущее поведение клиента. Финансовый показатель M, является вторичным показателем при прогнозировании дальнейшего поведения, однако он является первичным с точки зрения директ-маркетинговой компании, цель которой максимизация прибыли. Соответственно, заботясь о состоянии клиентской БД, компания так же должна иметь полную информацию о прибыльности тех или иных сегментов. Более того, так как RFM параметры связаны между собой и R является первичной характеристикой, а M — вторичной, то финансовая информация не напрямую, а косвенно может указывать на негативные тенденции, опережая ухудшение главного параметра на несколько шагов вперед, являясь слабым сигналом.
Разработанная методика применяется для выявления слабых сигналов негативных тенденций в эволюции клиентской БД, а так же дает в руки аналитику дополнительный инструмент финансового анализа БД. Методика основывается на сравнении в динамике финансовых и дополнительных поведенческих параметров, рассчитываемых в базисе сегментации S. Определим эти параметры.
Сегментация позволяет провести расчет следующих показателей в рамках сегментов за отчетный период L:
- TR — (transformation rate — коэффициент трансформации) % клиентов из данного сегмента, проявивших активность,
- Ords/customer — количество заказов на клиента из сегмента, Ords/active customer – количество заказов на заказавшего (активного) клиента из сегмента,
- Turnover, $ — оборот на сегмент,
- Turnover/customer, $ — оборот на клиента из сегмента,
- Turnover/ active customer, $ — оборот на активного клиента из сегмента,
- AOV, $ — средняя сумма заказа в сегменте.
Пользуясь дополнительными финансовыми и поведенческими показателями можно определить, какой сегмент приносит наибольшее количество средств, сколько заказов сделано клиентами из сегмента за отчетный период, какая средняя стоимость заказа. Как правило, сегмент активных клиентов образует 80% оборота, т.е. выполняется правило Парето 20/80.
Очевидно, что динамика каждого дополнительного финансового показателя в базисе сегментации S должна быть неотрицательной. В противном случае необходимо предпринимать меры для изменения направления тренда.
Оценка прибыльности маркетинговой акции
Как уже говорилось ранее, одной из целей сегментации является получение устойчивых статистических оценок прибыльности акций по сегментам.
Для оценки прибыльности проводится тестовая акция. Из каждого сегмента выбирается тестовая группа клиентов объема Ntesti, необходимого для получения оценки отклика на акцию с заданной точностью. Объем теста определяется на основе ожидаемого отклика в рамках сегмента, который известен по результатам прошлых акций, с помощью анализа мощности биномиального критерия. Результаты теста дают оценки откликов в каждом сегменте RRi, оценки средней стоимости заказа в акции AOVi, а так же распределение спроса на товары. На основе полученной информации оценивается прибыльность в каждом сегменте Ai и принимается решение о глубине экстраполяции теста. Некоторые сегменты (спящие, переходные) могут оказаться неприбыльными.
Апробация метода
В настоящем разделе приводится пример реального применения разработанных технологий для анализа и сегментации клиентской БД держателей карточек лояльности крупной московской сети ресторанов. По установленным правилам для получения карточки клиент должен поужинать в любом ресторане сети. При предъявлении счета клиент получает для заполнения анкету. В анкете запрашивается информация о возрасте, поле, семейном положении и образовании клиента. Кроме этого, у клиента спрашивают контактную информацию: адрес, электронный адрес, мобильный телефон. После заполнения анкеты клиент получает карту.
Карта дает возможность получения скидок. Скидка пропорциональна количеству средств, оставленных клиентом в ресторанах сети. При этом каждый счет с картой фиксируется в специально созданной клиентской БД. Клиенты наблюдаются в пассивном режиме. Дополнительных мероприятий (директ-маркетинговых рассылок) по мотивированию клиентов посещать рестораны не производится.
Задача работы заключается в создании устойчивой сегментации клиентской БД для мониторинга состояния клиентской БД и разработки целевых маркетинговых предложений для наиболее активной группы клиентов. Работа успешно выполнена с применением всех представленных в настоящей работе технологий. Сегментация клиентской БД внедрена на постоянной основе. Компания так же учла в своей стратегии ряд замечаний, и выводов по результатам анализа клиентской БД.
Прямым расчетом по всем клиентам БД можно показать, что средний интервал между соседними посещениями ресторанов равен 2 месяцам. Latency = 2. На таблице ниже представлена RF сегментация, построенная с применением разработанного метода.
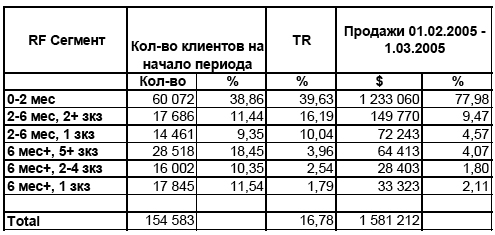
Таблица 4. Таблица с RF сегментацией на основе анализа жизненного цикла. Зеленым выделена активная зона R<2 мес (L), голубым — переходный сегмент (R:2-6 месяцев), синий и коричневый — спящие клиенты (R>6 мес). TR и объем продаж рассматриваются за 1 месяц.
На этапе сегментации по R выделен сегмент активных клиентов R
На этапе сегментации по F с применением правила отсечения одного заказа выделяется сегмент «безнадежных» спящих клиентов 6+,1 зкз. И подозрительных клиентов переходного сегмента 2-6 мес, 1 зкз. С применением правила отсечения по процентилям разбивается сегмент спящих клиентов на 6+, 2-4 зкз. и 6+, 5+ зкз. Последний сегмент представляет собой сегмент спящих клиентов наиболее пригонных для получения предложений. Это замечание подтверждает наблюдаемый TR для сегмента 6+, 4+ зкз. равный 4% по сравнению с 1,8% у худших спящих клиентов. Так же стоит обратить внимание, что наиболее активные клиенты с R<2 мес приносят 80% оборота, хотя сами составляют всего 40% от объема.
Для удобства обозначим сегмент активных клиентов как Active R<2 мес. Сегмент спящих клиентов представим и обозначим в виде двух Sleep (6+, 1-4 зкз.), Sleep best (6+,5+), и переходный сегмент обозначим Casual (2-6 мес.). Обозначим через NA (new arrivals) клиентов, которые приходят в БД за время между 2-мя последовательными пересчетами сегментации.
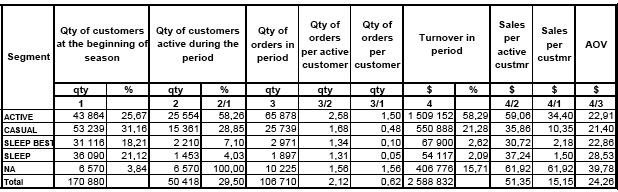
Таблица 5. Сегментация с рассчитанными дополнительными финансовыми параметрами за период наблюдения, равный 2 месяца
Полученная таблица сегментации является удобным средством анализа клиентской БД. С точки зрения TR сегменты контрастно различаются, т.е. различия в выделенных группах статистически значимы. Контрастно выделены сегменты наиболее активных и прибыльных клиентов (Active и NA). Эти два сегмента формируют основной оборот средств. У этих двух сегментов максимальный показатель orders per customer (заказов на клиента) 1,50 и 1,56 соответственно. Можно ожидать, что в следующем периоде клиенты из сегментов Active и NA сделают по 1,50 заказов с объемом продаж на клиента 34,4 USD и 62 USD соответственно. Интересно заметить, что чем больше заказов на активного клиента (Qty of orders per active customer) тем меньше AOV (средняя сумма заказа). Это говорит о том, что имея ограниченный «кошелек» более активные сегменты должны делить свои затраты между несколькими заказами (2,58 для Active) в то время как спящие клиенты тратят свои средства всего на 1,31 заказа.
Для проверки устойчивости сегментации с частотой 2 месяца были построены «слепки» клиентской БД в виде, представленном в Таблица 5 за всю историю программы лояльности. Замечено, что ключевые и дополнительные финансовые показатели в рамках сегментов флуктуируют в пределах 5% отклонений.
Выводы
Анализ существующих методов сегментации клиентских баз данных показал, что хотя современные статистические методы, успешно применяемые в различных компаниях, и позволяют решать задачи сегментации, но они обладают рядом существенных недостатков.
Недостатки известных методов сегментации заключаются в «плавающих» границах сегментов. Это обстоятельство, вообще говоря, не позволяет корректно тестировать и принимать решения об экстраполяции маркетинговых акций. Кроме того, сегменты с плавающими границами не сравнимы между собой в динамике, т.е. отсутствует возможность построения сегментационного базиса, что не позволяет прогнозировать состояние клиентской БД в будущем.
Настоящая работа посвящена созданию метода сегментации, который бы позволил устранить недостатки известных ныне методов. Приводится постановка задачи сегментации как задача бинарной классификации с учителем и наличием миноритарного целевого класса. Систематизированы существующие выводы различных исследователей об RFM переменных и их взаимодействии в постулаты клиентского поведения. Особое внимание уделяется характеристике цикличности клиентского поведения L (latency) и переменной, характеризующей жизненный цикл клиента R. На основании полученных результатов построен метод RF сегментации, который базируется на жизненном цикле клиента. По построению сегментация обладает фиксированными границами, что решает проблему внедрения сегментационного базиса для тестирования и экстраполяции маркетинговых акций, а так же возможностей прогнозирования состояния БД.
В рамках созданной модели клиентской БД разработаны методики, позволяющие анализировать состояние БД и моделировать состояние БД в будущем. Разработан метод динамического сравнения сегментов БД по объему. Определены дополнительные финансовые и поведенческие характеристики и методы динамического сравнения финансовых характеристик как слабых сигналов кардинального ухудшения состояния БД. Приведен пример практического применения разработанных технологий для сегментации клиентской БД держателей дисконтных карт московской сети ресторанов.
* * * * *
Автор считает своим долгом выразить глубокую благодарность научному директору компании «СтатСофт Раша», к.ф.-м.н. Боровикову Владимиру Павловичу, генеральному менеджеру компании «СтатСофт Раша» Онищенко Марине Валентиновне и научному руководителю, проректору МИЭМ, д.т.н. Путилову Георгию Петровичу за постановку задачи, предоставление рабочих инструментов и постоянное внимание к работе.
Литература
- Айвазян С.А., Мхитарян В.С., Теория вероятностей и прикладная статистика, т 1,2. М.: «Юнити», 2001.
- Айвазян С.А., Енюков И.С., Мешалкин Л.Д., Прикладная статистика, Основы моделирования и первичная обработка данных, М.: Финансы и статистика, 1983.
- Айвазян С.А., Бухштабер В.М., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Классификация и снижение размерности. М.: Финансы и статистика, 1989.
- Афифи А., Эйзенс С. Статистический анализ. Подход с использованием ЭВМ. М.:Мир,1982.
- Боровиков В.П. STATISTICA: искусство анализа данных на компьютере, «Питер», 2003.
- Вуколов Э.А. Основы статистического анализа, М.: ИД «Форум», 2004.
- Головко В.А. Нейронные сети: обучение, организация и применение. Кн. 4, Учеб. Пособие для вузов/ Общая ред. Галушкина А.И. М.:ИПРЖР, 2001.
- Дюк В., Самойленко А. Data Mining: учебный курс СПб.: 'Питер', 2001.
- Сошникова Л.А., Тамашевич В.Н., Уебе Г., Шеффер М. Многомерный статистический анализ в экономике: Учеб. Пособие для вузов/Под ред. Проф. В.Н. Тамашевича. М.: ЮНИТИ-ДАНА, 1999.
- Bing Liu, Yiming Ma, Ching-Kian Wong, and Philip S. Yu. Scoring the Data Using Association Rules. Applied Intelligence, Vol 18, No. 2, 119-135, 2003.
- David Sheppard Associates, Inc., The New Direct Marketing: How to Implement a Profit-Driven Database Marketing Strategy, Boston: McGraw-Hill, 1999.
- Dirk Van den Poel, Predicting Mail-Order Repeat Buying: Which Variables Matter? Ghent University, Faculty of Economics and Business Administration, Department of Marketing, Hoveniersberg, working papers, D/7012/29, 2003
- Hughes, Arthur M., “Boosting Response with RFM”, Marketing Tools, 1996.
- John R. Miglautsch. Thoughts on RFM scoring. The Journal of Database Marketing, Volume 8, Number 1, 2000.
- Schmid, J., A. Weber, Desktop Database Marketing, NTC Business Books, Chicago, IL, 1997.
- R. Agrawal, T. Imielinski, A. Swami. Mining Associations between Sets of Items in Massive Databases. In Proc. of the 1993 ACM-SIGMOD Int’l Conf. on Management of Data, 207-216., 1993
- R. Agrawal, R. Srikant. Fast Discovery of Association Rules, In Proc. of the 20th International Conference on VLDB, Santiago, Chile, September 1994.
- Rossi, Peter E., Robert McCulloch., Greg Allenby (1996), “The Value of Household Information in Target Marketing”, Marketing Science, 15 (Summer), 1996.
- Sara Madeira, João M. Sousa, “Comparison of Target Selection Methods in Direct Marketing”. In Proc. of European Symposium on Intelligent Technologies, Hybrid Systems and their Implementation on Smart Adaptive Systems, Eunite'02, Albufeira, Portugal, September 2002.
- Subom Rhee, Gary J. Russell. Measuring Household Response in Database Marketing: A Latent Construct Approach, The University of Iowa, Research highlights 2003.
Exploring KAYA88 Slot Game Malaysia: Best Titles with Link Free Credit Slot Bonuses
Find the Top 10 IT Staffing Agencies
Top Modeling Agencies: Fulfill Your Dream
Top Ranked CNA Travel Agencies in 2024
10 Best Recruitment Agencies: Find the Best Talents
Рубрики
- Авторские колонки
- Интернет-технологии в B2B
- Исследования в маркетинге
- Маркетинг в B2B-среде
- Маркетинг во время кризиса
- Маркетинговые коммуникации
- Обзоры B2B-рынков
- Обзоры товаров и услуг
- Организация маркетинга
- Особенности B2B-среды
- Практические кейсы
- Продвижение, реклама и PR

Пресс-релизы
- Exploring KAYA88 Slot Game Malaysia: Best Titles with Link Free Credit Slot Bonuses
- STATUS TRAVEL — Надежные пассажирские перевозки с комфортом и безопасностью
- Якісні одноразові пелюшки для комфорту та безпеки
- Межкомнатные двери – на что обращать внимание при выборе | Дверной Олимп
- Інтернет-магазин adidas: новий етап досконалості у світі спорту
HowTo


О проекте B2Blogger
B2Blogger.com — «блогоиздание» о промышленном В2В-маркетинге, представляющее исключительную информацию и сервисы специалистам в сфере маркетинга, рекламы и PR, руководителям предприятий, консультантам по бизнесу, преподавателям и студентам учебных заведений.


